향상도 곡선(Lift Curve)
랜덤모델과 비교하여 해당 모델의 성과가 얼마나 향상되었는지 구간별로 파악하기 위한 그래프
좋은 모델일수록, 큰 값에서 시작하여 급격히 감소한다.
install.packages(‘ROCR’)
> iris_bin1<-subset(iris, Species=='setosa'|Species=='versicolor')
> iris_bin1$Species<-ifelse(iris_bin1$Species=='setosa', 1, 0)
> iris_bin1<-iris_bin1[, c(1, 2, 5)]
> index<-sample(2, nrow(iris_bin1), replace=T, prob=c(0.7, 0.3))
> train<-iris_bin1[index==1, ]
> test<-iris_bin1[index==2, ]
> library(rpart)
> result<-rpart(Species~., data=train)
> pred<-predict(result, newdata=test)
> test$pred<-pred
> library(rpart)
> result<-rpart(Species~., data=train)
> pred<-predict(result, newdata=test)
> test$pred<-pred
> library(ROCR)
> lift_value<-prediction(test$pred, test$Species)
> plot(performance(lift_value, 'lift', 'rpp'))
> abline(v=0.4, lty=2, col='blue')
> abline(v=0.58, lty=2, col='blue')
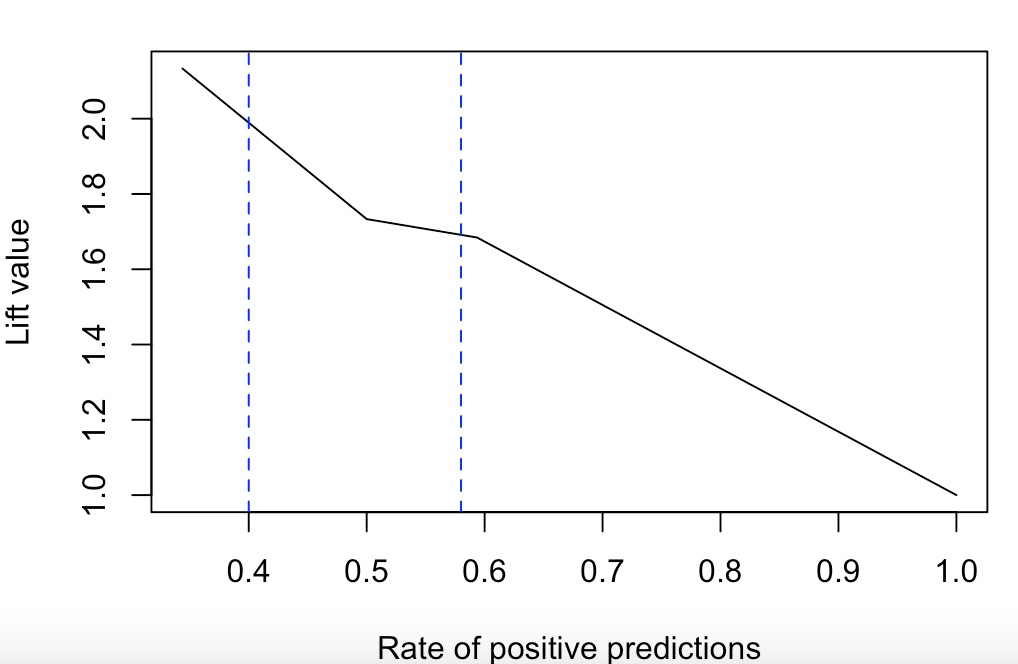
약 40% 데이터에 대해서 1.9배 정도의 좋은 예측력을 갖고 있다
약 58% 데이터에 대해서 1.7배 정도의 좋은 예측력을 갖고 있다